It’s been more than 10 years since I presented one of my first papers at the first conference on Automated Knowledge Base Construction (AKBC) in Grenoble in 2010 😬
I still remember how intimidated I felt by all those research stars with their proven track record, amazing papers, citations - and me, with my little paper that I needed to correct at last minute because I made a severe error in the evaluation code (my passion for automated tests was born on that day 🐥). Still, I had a really good time, met many nice people and in the end managed to present my work.
10 plus years later, having switched from research and the Wikipedia-domain to industry and healthcare data, the number of challenges have rather increased, especially when tackling German data. In the (almost entire) absence of publicly available structured data, the need for automated knowledge base construction is even more pressing. That’s why I went to London to attend AKBC2022! Great schedule, great location, Great Britain, here I come! 🙌
 Barbican Centre feels like a mixture of an old James Bond Movie and a huge botanic garden - amazing!
Barbican Centre feels like a mixture of an old James Bond Movie and a huge botanic garden - amazing!
The remainder of this post is a (heavily biased) collection of the talks, links, repos, papers, (handy cam) pictures, ideas, thoughts… that I found most intersting. If you are looking for a detailed summary of the conference, you will not find that here, sorry 🤷♀
Talks, Keynotes & Papers
Temporal and Multilingual Knowledge Graphs
The world is dynamic and Knowledge Graphs (KG) should reflect this time-varying nature. Temporal KGs provide a mechanism to represent this dynamism through time-scoped edges. While question answering over traditional KGs have received quite a bit of attention, QA over Temporal KGs is still in early stages. […]
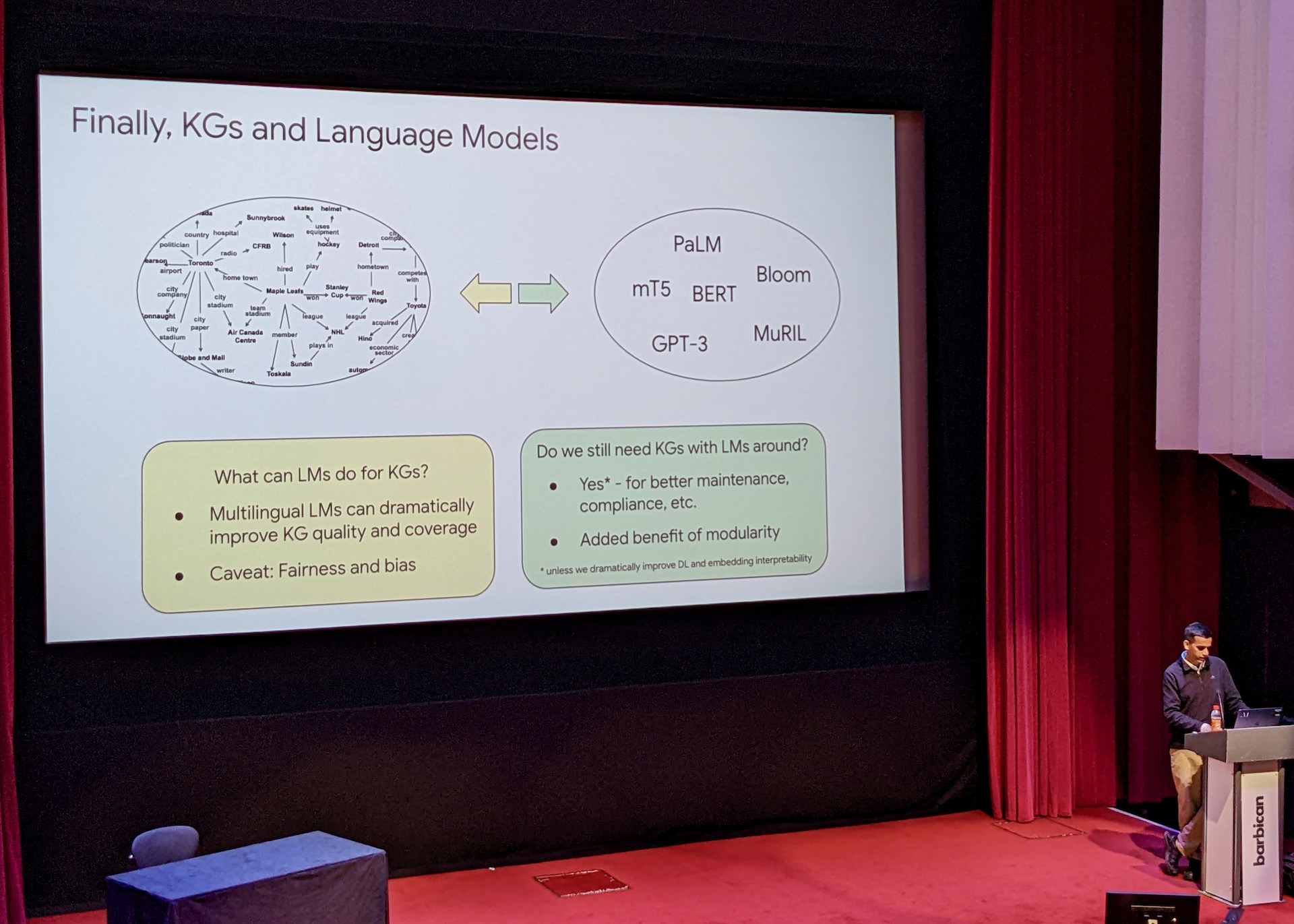 Knowledge Graphs and Language Models.
Knowledge Graphs and Language Models.
CascadER: Cross-Modal Cascading for Knowledge Graph Link Prediction
🔈 Tom Hope
Knowledge graph (KG) link prediction is a fundamental task in artificial intelligence, with applications in natural language processing, information retrieval, and biomedicine. Recently, promising results have been achieved by leveraging cross-modal information in KGs, using ensembles that combine knowledge graph embeddings (KGEs) and contextual language models (LMs). […]
- Cross modal: combine knowledge graph embeddings and text (language models).
 Example relation: "Aspirin" treats what?
Example relation: "Aspirin" treats what?
- more on CascadER
Data driven policy for pandemic response: data, knowledge, and action well outside of the ivory tower
🔈 Jesse Tenenbaum, Chief Data Office at DHHS
The “central dogma” of informatics, it has been said, is turning data into information and information into knowledge. Some take this framework further- knowledge informs action. Moreover, in the Learning Health System model, action begets more real-world data, which can be converted into information, etc. […]
Really great talk with lots of puns and fun anecdotes!
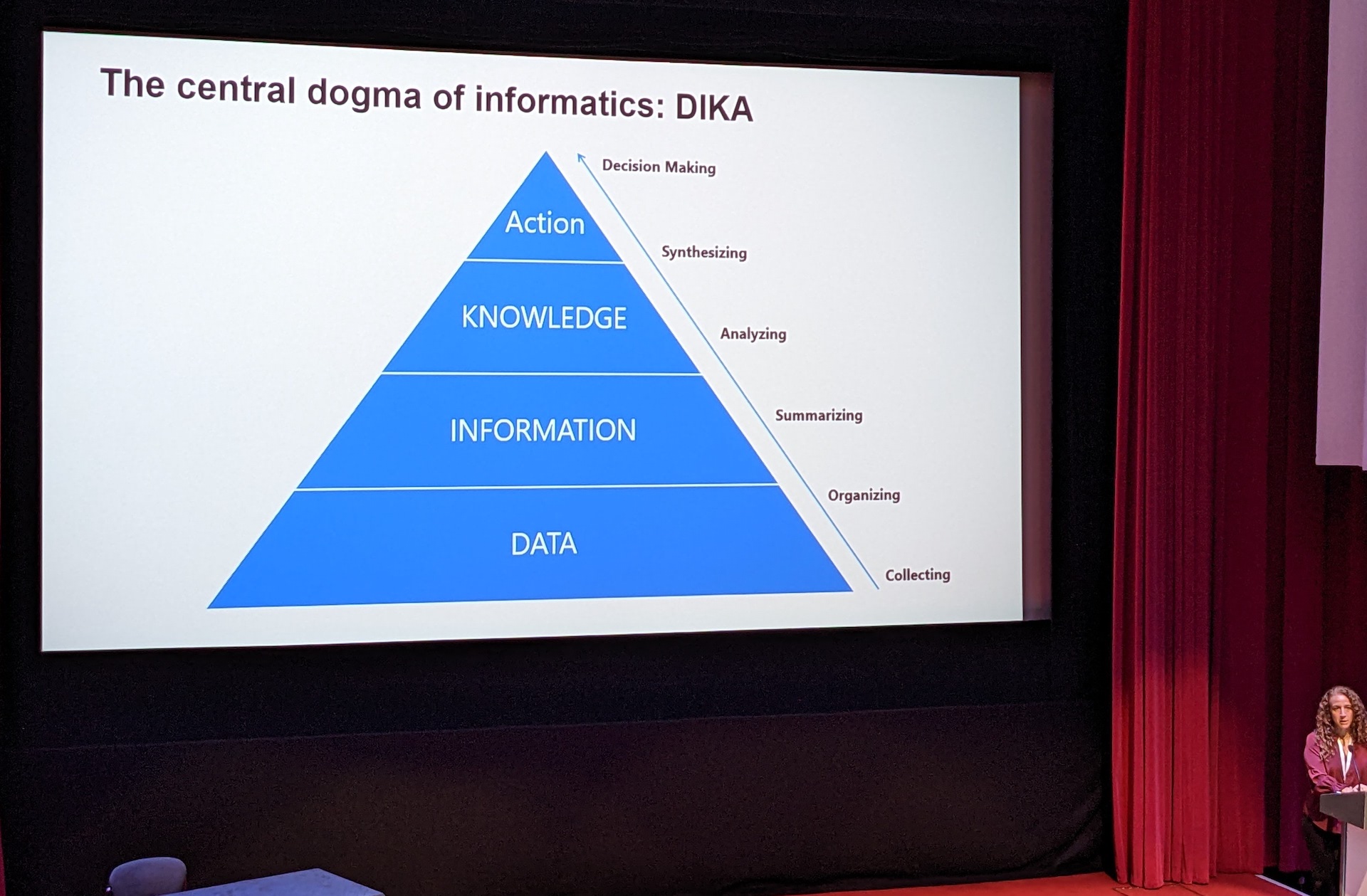 DIKA: Data, Information, Knowledge, Action
DIKA: Data, Information, Knowledge, Action
 Data Strategy Framework
Data Strategy Framework
 Probabilistic fuzzy match between data silos: use soundex to handle typos
Probabilistic fuzzy match between data silos: use soundex to handle typos
- Worth reading: NCDHHS’s Data Sharing Guidebook
- Soundex
Project Alexandria in Viva Topics: AKBC in practice
At AKBC 2019, we presented Project Alexandria as a solution to inferring a knowledge base completely automatically from unstructured data. Since then, we have built Alexandria into the heart of a new Microsoft product called Viva Topics, launched last year. Viva Topics automatically constructs a knowledge base from an organization’s documents and intranet pages, and surfaces it across a wide range of Microsoft applications including SharePoint, Teams, Outlook and more. […]
 Generative model of Entity Llinking
Generative model of Entity Llinking
- Knowledge Base construction without looking at the data
- Entity fragments: pieces of the same entity that are not yet merged
- Supports multiple languages (tokenization and things like this might be needed to be adapted)
- More about Project Alexandria
Trustworthy Natural Language Generation with Communicative Goals
While recent work in large language models have made natural language generation fluent, these models suffer from content “hallucination”, where model-generated statements are not attributable to sources in communicative scenarios (e.g. summarization, question answering and responses in dialogue systems) […]
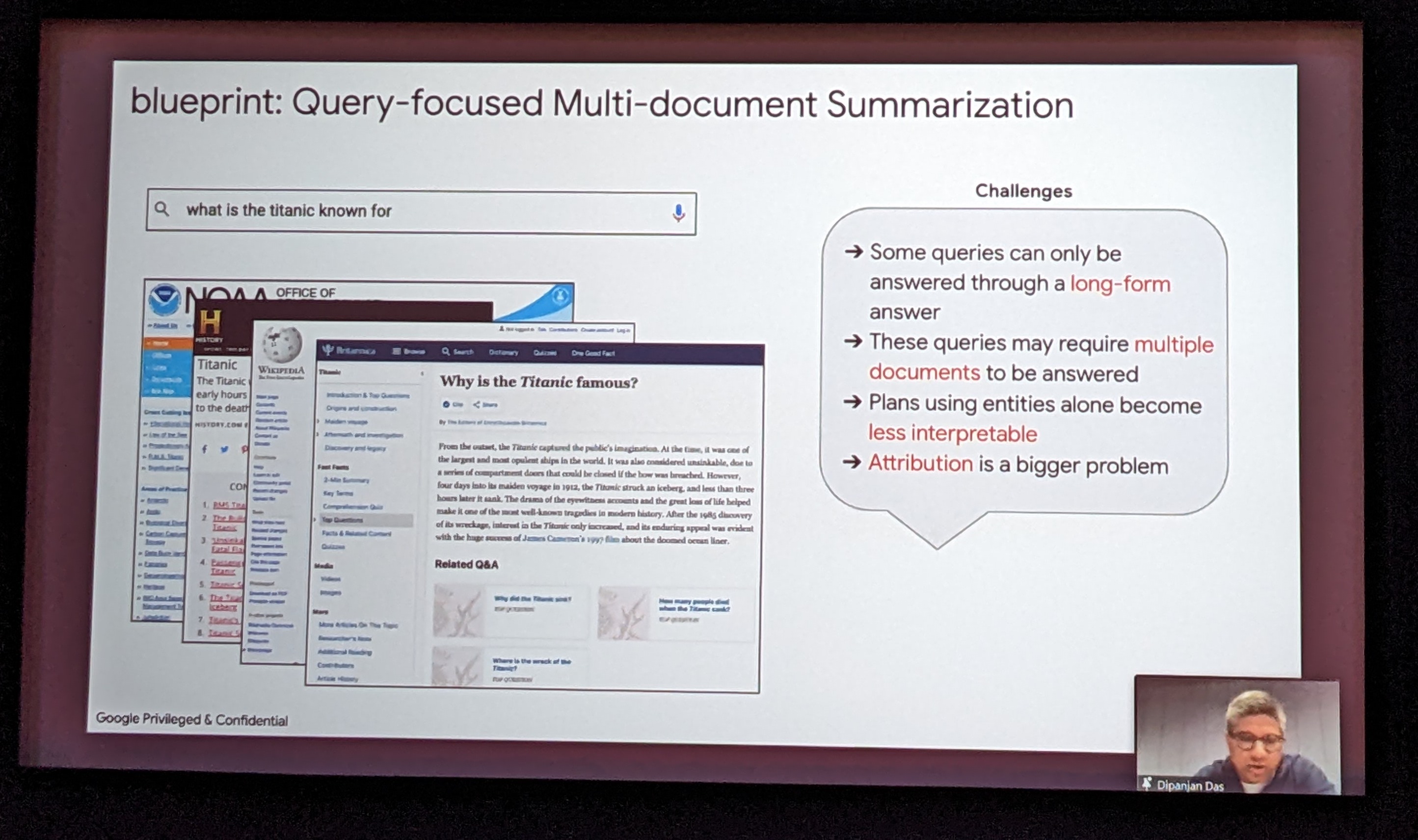 Query-focused Multi Document Summarization
Query-focused Multi Document Summarization
 Informative Dialogue Agents - a chatGPT preview
Informative Dialogue Agents - a chatGPT preview
NLP for Science: Advances and Challenges
With over one million papers added every year to the PubMed biomedical index alone — the explosion of scholarly knowledge presents tremendous opportunities for accelerating research across the sciences. However, the complexity of scientific literature presents formidable challenges for existing AI and NLP technologies, limiting our ability to tap into this vast treasure trove of information. In this talk, I will present our recent work toward helping researchers and clinicians make use of knowledge embedded in the literature. […]
Literature-Augmented Clinical Outcome Prediction
- BEEP (Biomedical Evidence- Enhanced Predictions): automatically retrieve patient-specific literature based on intensive care EHR notes, use the literature to enhance clinical outcome prediction
- adding literature significantly reduces error (over 25% increase in precision@top-k scores)
- potential next step: incorporate evidence identification and inference directly into retrieval and predictive models
 Retrieval-augmented Language Models for clinical outcome prediction
Retrieval-augmented Language Models for clinical outcome prediction
 Integration of graph and text modalities
Integration of graph and text modalities
🤔 Does this additional context also help for less complicated cases? I.e. patients that are not in the ICU?
Keeping LMs in sync with the real world
Our world is open-ended, non-stationary and constantly evolving; thus what we talk about and how we talk about it changes over time. This inherent dynamic nature of language comes in stark contrast to the established static paradigm of NLP. This staticness has led over the years to a number of peculiarities; our models are “stuck” to the time they were trained, our systems are not designed to be easily adaptive, and our benchmarks further perpetuate this vicious circle.
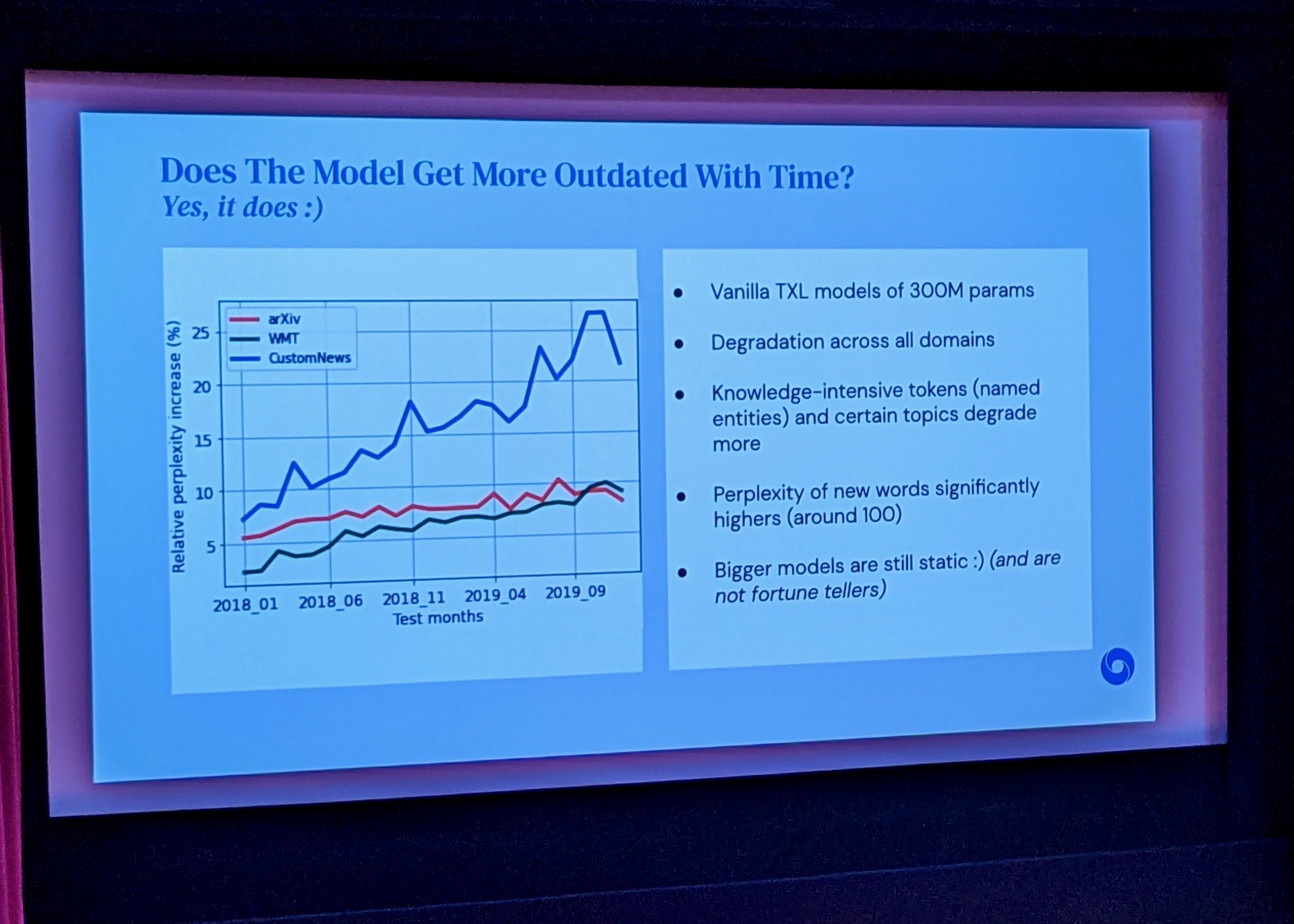 Language Models get outdated over time
Language Models get outdated over time
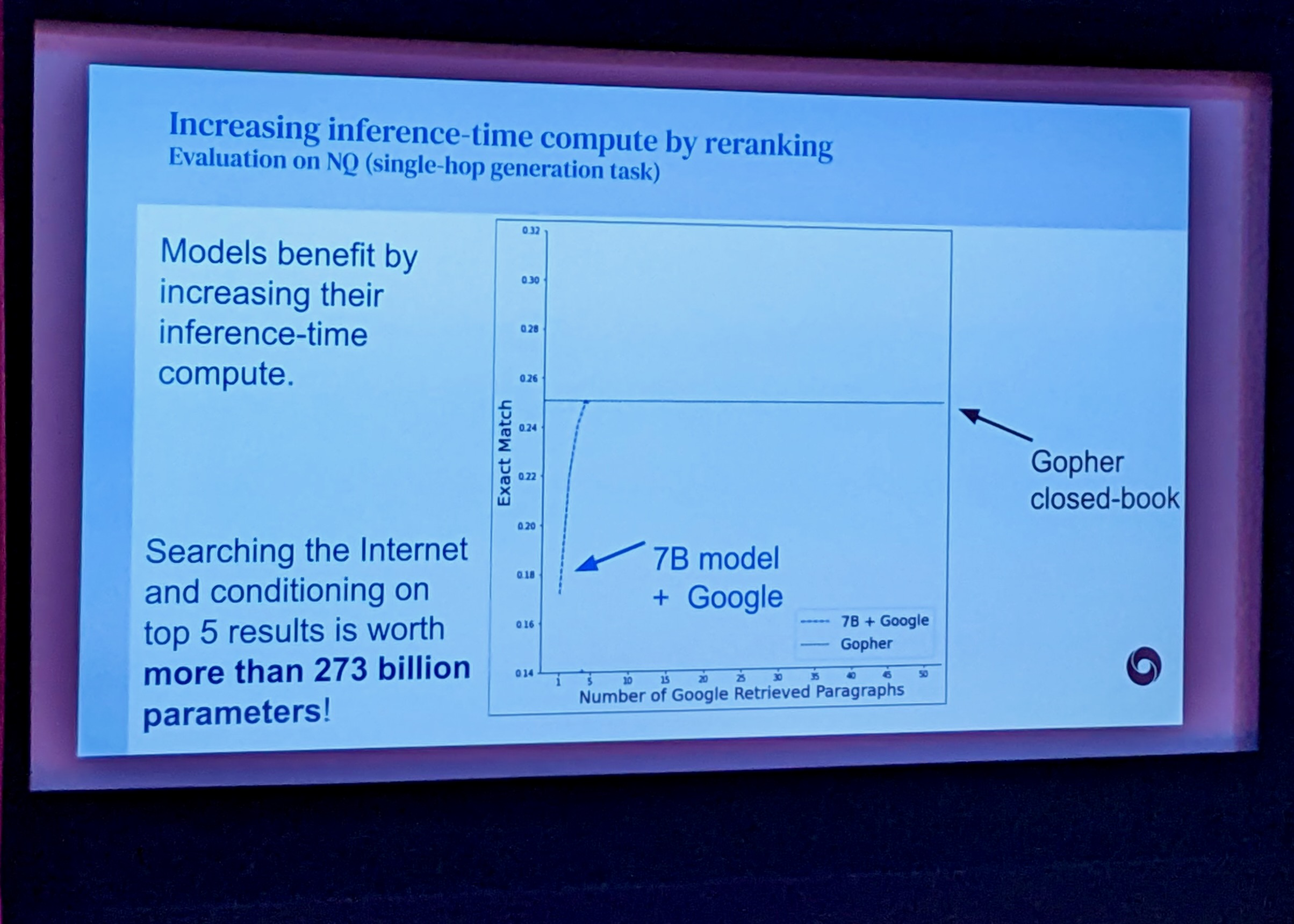 Searching the Internet and conditioning on top 5 results is worth more than 273 billion parameters!
Searching the Internet and conditioning on top 5 results is worth more than 273 billion parameters!
Approach uses google queries but is therefore not strictly reproducible, as google results are prone to change: „If we stick on being reproducible, we are not going to make progress.“
Anti-vaccination arguments: a conceptual taxonomy and a machine-learning model
[…] Through a preregistered systematic literature review and thematic analysis of anti-vaccination arguments, we developed a hierarchical taxonomy that relates common arguments and themes to 11 attitude roots that explain why an individual might express opposition to vaccination. We further validated our taxonomy on COVID-19 anti-vaccination misinformation, through a combination of human coding and machine learning using natural language processing algorithms. […]
 Anti-vaccination arguments: a conceptual taxonomy and a machinelearning model
Anti-vaccination arguments: a conceptual taxonomy and a machinelearning model
QuALITY: Question Answering with Long Input Texts, Yes!
To enable building and testing models on long-document comprehension, we introduce QuALITY, a multiple-choice QA dataset with context passages in English that have an aver- age length of about 5,000 tokens, much longer than typical current models can process. Un- like in prior work with passages, our ques- tions are written and validated by contributors who have read the entire passage, rather than relying on summaries or excerpts. […]
Entity-Centric Query Refinement
We introduce the task of entity-centric query refinement. Given an input query whose answer is a (potentially large) collection of entities, the task output is a small set of query refinements meant to assist the user in efficient domain exploration and entity discovery.

Few-Shot Inductive Learning on Temporal Knowledge Graphs using Concept-Aware Information
Knowledge graph completion (KGC) aims to predict the missing links among knowledge graph (KG) entities. Though various methods have been developed for KGC, most of them can only deal with the KG entities seen in the training set and cannot perform well in predicting links concerning novel entities in the test set.
Poster Session
 Poster session in the Barbican Conservatory, London's second largest botanic garden.
Poster session in the Barbican Conservatory, London's second largest botanic garden.
Pseudo-Riemannian Embedding Models for Multi-Relational Graph Representations
This basically can handle two super similar entities that are not to be linked (something you can not do with Gaussian spaces). Example: genes that are triggered by the same transcription factor but result in totally different proteins.
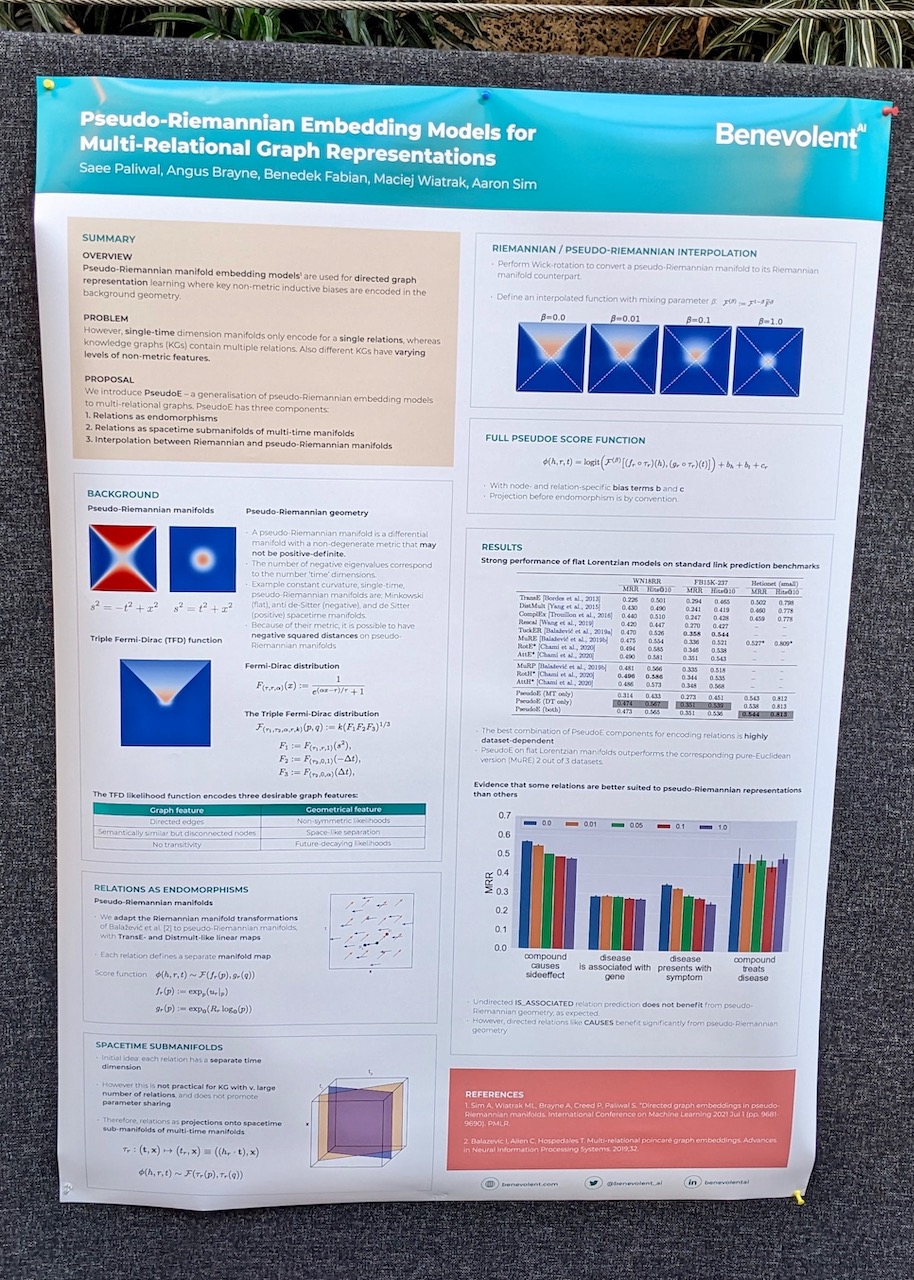 Pseudo-Riemannian Embedding Models for Multi-Relational Graph Representations
Pseudo-Riemannian Embedding Models for Multi-Relational Graph Representations
UnCommonSense: Informative Negative Knowledge about Everyday Concepts
Enriching commonsense knowledege bases with informative negated statements boosts their usability.
 UnCommonSense: Informative Negative Knowledge about Everyday Concepts
UnCommonSense: Informative Negative Knowledge about Everyday Concepts
Other interesting papers
- Generative Multi-hop Retrieval, EMNLP 2022
- Discovering Fine-Grained Semantics in Knowledge Graph Relations, CIKM 2022
- Decoupling Knowledge from Memorization: Retrieval-augmented Prompt Learning, NeurIPS 2022
- CODEC: Complex Document and Entity Collection, SIGIR 2022
- Towards Realistic Low-resource Relation Extraction: A Benchmark with Empirical Baseline Study, EMNLP 2022
- Zero-shot Word Sense Disambiguation using Sense Definition Embeddings, ACL 2019
Impressions
 London, Barbican Centre
London, Barbican Centre
 London Bridge
London Bridge
 London Tower Bridge
London Tower Bridge
 London Tower
London Tower
… I spent a substantial amount of time waiting for tubes due to a flooding
… I am still dumbfounded by the hotel prices in London 😑